AIエージェント活用実践編 / Workflow と Agent の使い分け — 何を自動化するかの判断
実装規模感とコスト意識
無料公開レッスン / 読了目安 5 分
学習のねらい
AI システムを開発する際、どのパターンを選ぶかによって、必要な実装期間やコストが大きく変わります。 特に、LLM の利用には API コール数やトークン消費に応じて費用が発生するため、コスト意識を持って設計することが重要です。 このレッスンでは、各パターンの実装規模感と、コストとのバランスを考慮した選択方法について学びます。
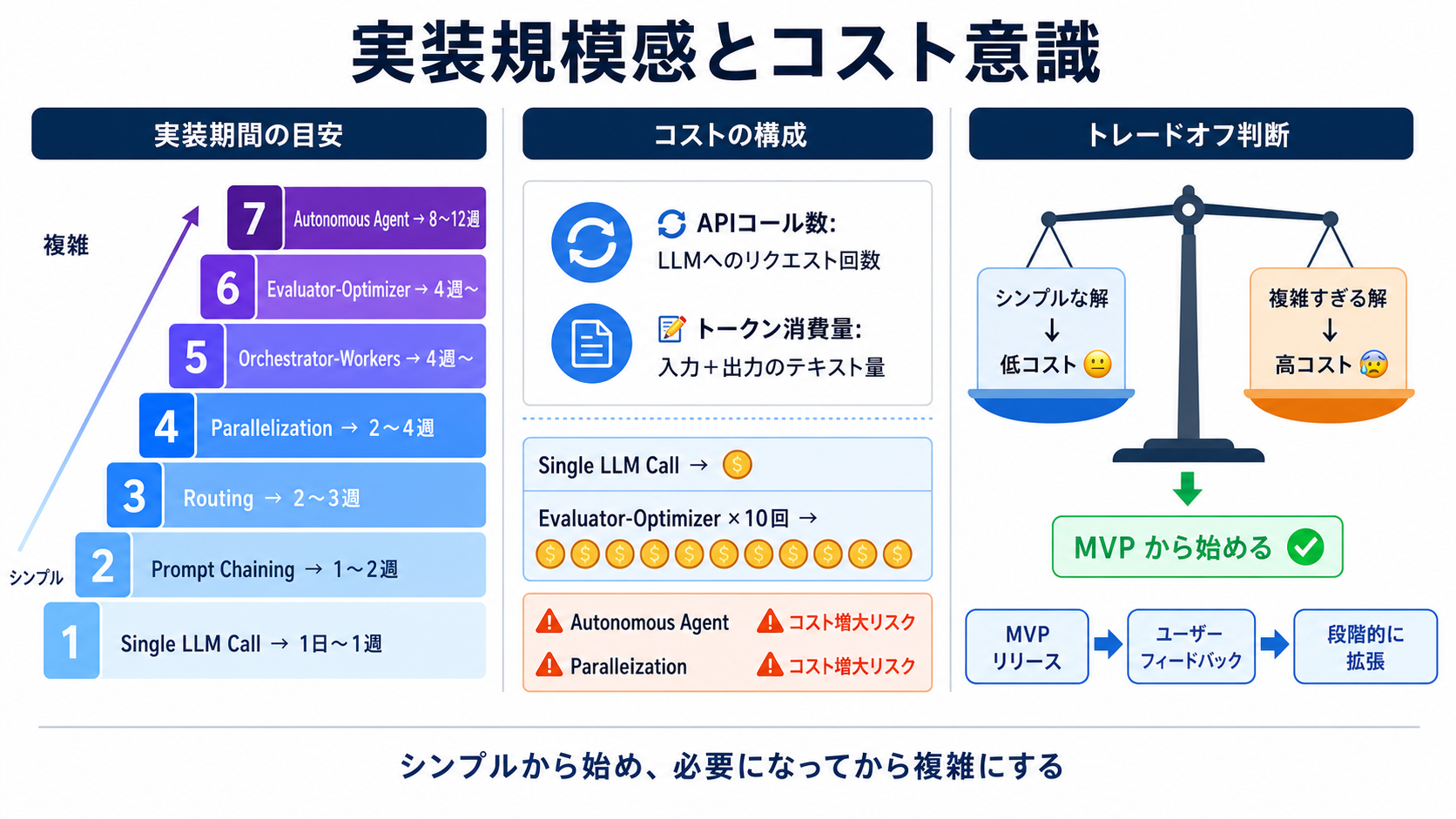
実装期間の目安
前レッスンでも触れましたが、Anthropic の提唱する6つのパターンには、それぞれおおよその実装期間目安があります。
| パターン | 実装期間目安 |
|---|---|
| Single LLM call | 1日〜1週 |
| Prompt Chaining | 1〜2週 |
| Routing | 2〜3週 |
| Parallelization | 2〜4週 |
| Orchestrator-Workers | 4週〜 |
| Evaluator-Optimizer | 4週〜 |
| Autonomous Agent | 8〜12週 |
この表から分かるように、Autonomous Agent のような複雑なパターンは、実装に数ヶ月かかる可能性があります。 これは、システムの設計だけでなく、予期せぬ挙動への対応、デバッグ、安全性確保など、多くの工数が含まれるためです。 「シンプルから始め、必要になってから複雑にする」という原則は、この実装期間とコストを抑える上でも非常に重要です。
API コール数とトークン消費 — 目に見えないコスト
LLM を利用する際のコストは、主に API コール数 と トークン消費量 によって決まります。
- API コール数: LLM にリクエストを送る回数です。例えば、Prompt Chaining で3つの LLM 呼び出しを行う場合、1回の処理で3回の API コールが発生します。
- トークン消費量: LLM とのやり取り(入力プロンプトと出力)で使われるテキストの量です。テキストは「トークン」という単位で数えられ、モデルや利用地域によって1トークンあたりの料金が変わります。
複雑なパターン、特に反復的な処理や試行錯誤を伴うパターン(Evaluator-Optimizer, Autonomous Agent)は、必然的に API コール数やトークン消費量が増えやすくなります。 例えば、Evaluator-Optimizer で10回のリライトを繰り返せば、それだけで通常の10倍のコストがかかる可能性があります。 また、Parallelization も複数の LLM を並列で動かすため、同時に多数の API コールが発生し、コストが増大しやすい傾向があります。
ユーザー満足度とのトレードオフ
コストを抑えることは重要ですが、それと同時にユーザーがどれだけ満足するか、という視点も忘れてはいけません。
- シンプルすぎる解: コストは低いですが、ユーザーの期待に応えられず、最終的な満足度が低い可能性があります。例えば、複雑な質問に対して Single LLM call で不十分な回答しか返せない場合などです。
- 複雑すぎる解: 高いコストがかかる割に、ユーザー体験が期待ほど向上しない、あるいは開発期間が長すぎてリリースが遅れる、といった事態も起こりえます。
このバランスを見極めるには、まずシンプルな MVP(Minimum Viable Product、実用最小限の製品)でユーザーに価値を届け、そのフィードバックを元に段階的に機能を拡張していくアプローチが有効です。 「この機能はユーザーにとって本当に必要か?」「この複雑なパターンを採用するほどの価値があるか?」と常に問いかけながら進めましょう。
まとめ
AI システムの設計では、実装期間と API コール数、トークン消費量といったコストを意識することが不可欠です。 シンプルなパターンから始め、ユーザーのニーズとコストのバランスを見ながら、段階的に複雑さを増やしていくのが賢明なアプローチです。
関連動画
【2026年4月版】今触るべきAIエージェント完全ガイド!汎用と開発で分ける正解ルートを徹底解説
AIエージェントの5つのレベル - シンプルなLLM呼び出しからマルチエージェントシステムまで